什么是决策树
决策树模型由一系列的问题构成,通过问题的回答结果不断地对输入数据进行区域划分,并以树状结构展示数据所在的区域,树的每一个叶子结点就是一个区域。因此,如果我们根据训练数据构建出一颗决策树,也就是划分出不同特征值组合对应的区域,那么给出新的数据,我们只要根据该决策树的规则,找出新数据所在的区域即可。
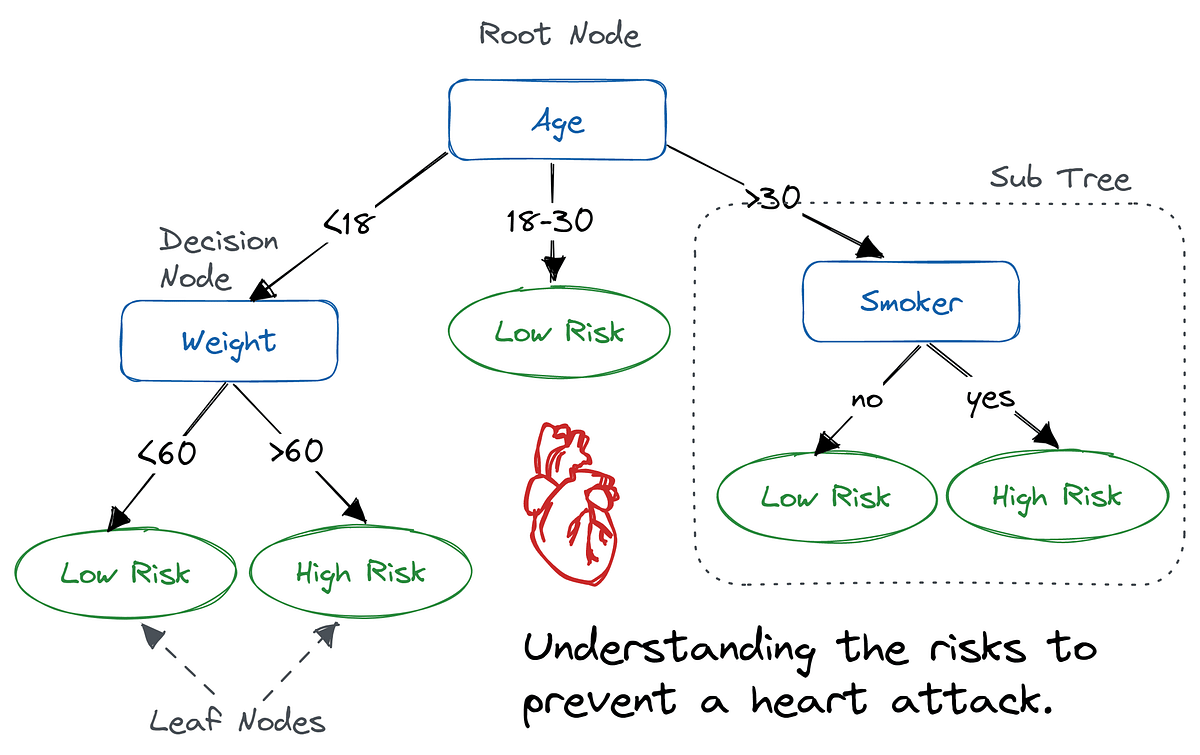
CART 决策树
CART 树介绍
CART 决策树既可以用于回归和分类,是最常用的决策树。先介绍回归树,它表示我们要求的输出结果是一个实数值。CART 树假设决策树都是二叉树,在每一个结点,对于连续型特征,则将其与一个阈值进行比较,小于阈值划为左子树,大于则划为右子树;对于离散型特征,则将结点划分为属于或不属于该类别。
一个回归树可以表示为
$$f(\mathbf{x}; \boldsymbol{\theta})=\sum_{i=1}^{I}w_i \mathbb{I}(\mathbf{x} \in R_i),$$这里,\(R_i\) 表示第 \(i\) 个叶结点所在的区域,\(w_i\) 表示该结点的输出值,是对应区域所有实例输出的均值:
$$w_i = \frac{\sum_{n=1}^{N}y_n \mathbb{I}(\mathbf{x} \in R_i)}{\mathbb{I}(\sum_{n=1}^{N}\mathbf{x} \in R_i)},$$\(\boldsymbol{\theta}=\{(R_i,w_i): i = 1:I\}\) 是我们需要学习的参数,表示树的结构,各个划分区域的输出值,\(I\) 表示结点的数量。
对于分类树,将输出均值改为输出各类别的概率分布。
CART 树生成
为了学习树的结构,对区域进行划分,我们需要最小化损失函数:
$$\mathcal{L}(\boldsymbol{\theta})=\sum_{n=1}^{N}\ell(y_n, f(\mathbf{x}_n; \boldsymbol{\theta}))=\sum_{n=1}^{N}\sum_{\mathbf{x}_n \in R_i}\ell(y_n, w_i).$$从最后一个求和号可以看到,这需要我们学习一个树的结构,因此该损失函数不可导,难以优化。实际上这是一个 NP-complete 问题,因此通常采用贪心算法,一个结点一个结点进行优化。
假设我们现在处于结点 \(i\),令 \(\mathcal{D}=\{(\mathbf{x}_n, y_n) \in N_i\}\) 表示结点 \(i\) 这时候的数据,现在考虑如何对结点进行划分能够使得损失最小。
根据上一节所说的,如果第 \(j\) 个特征是连续值,可以通过将该值与一个阈值 \(t\) 进行比较来对结点 \(i\) 进行划分,这里的阈值通常在特征的取值范围中选取。那么左右子树的数据分别为 \(\mathcal{D}_{i}^{L}(j,t)=\{(\mathbf{x}_n, y_n) \in N_i: x_{n,j} \leq t\}\), \(\mathcal{D}_{i}^{R}(j,t)=\{(\mathbf{x}_n, y_n) \in N_i: x_{n,j} > t\}\)。
如果第 \(j\) 个特征是离散值,有 \(K_j\) 种类别,那么将检查该特征属于某个类或者不属于该类(即是或否,因为 CART 树假设均为二叉树)。因此,左右子树的数据分别为 \(\mathcal{D}_{i}^{L}(j,t)=\{(\mathbf{x}_n, y_n) \in N_i: x_{n,j} = t\}\), \(\mathcal{D}_{i}^{R}(j,t)=\{(\mathbf{x}_n, y_n) \in N_i: x_{n,j} \neq t\}\)。如果不假设二叉树,对类别进行多种划分,则可能会出现 data fragmentation 现象,在某些子树中只有很少的数据,分得太细,容易导致过拟合。
根据上述步骤可以计算在结点 \(i\) 根据第 \(j\) 个特征和阈值 \(t\) 进行划分的左右子树为 \(\mathcal{D}_{i}^{L}(j,t)\) 和 \(\mathcal{D}_{i}^{R}(j,t)\) ,然后我们根据以下方式选择最佳的划分特征 \(j_i\) 和划分阈值 \(t_i\):
$$(j_i, t_i) = \arg \min_{j} \min_{t} \frac{|\mathcal{D}_{i}^{L}(j,t)|}{|\mathcal{D}_{i}|}c(\mathcal{D}_{i}^{L}(j,t)) + \frac{|\mathcal{D}_{i}^{R}(j,t)|}{|\mathcal{D}_{i}|}c(\mathcal{D}_{i}^{R}(j,t)).$$对于回归问题,在结点 \(i\) 划分的损失可以使用均方误差 MSE:
$$c(\mathcal{D}_{i})=\frac{1}{|\mathcal{D_i}|} \sum_{n \in N_i}(y_n - w_i)^2.$$对于分类问题,计算基尼指数(Gini index)来衡量损失:
$$\text{Gini}(p)=\sum_{c=1}^{C}p_c(1-p_c)=1-\sum_{c=1}^{C}p_c^2, \\ \text{Gini}(\mathcal{D_{i}})=1-\sum_{c=1}^{C}(\frac{|\mathcal{D_{i,c}}|}{|\mathcal{D_{i}}|})^2, \\ \text{Gini}(\mathcal{D_{i}}, A)=\frac{|\mathcal{D}_{i}^{L}|}{|\mathcal{D_{i}}|} \text{Gini}(\mathcal{D}_{i}^{L}) + \frac{|\mathcal{D}_{i}^{R}|}{|\mathcal{D_{i}}|} \text{Gini}(\mathcal{D}_{i}^{R}),$$其中,\(p_c\) 是样本属于第 \(c\) 类的概率,\(\mathcal{D_{i,c}}\) 是数据集 \(\mathcal{D_{i}}\) 中属于第 \(c\) 类的样本。
直观上,Gini 指数反映了从数据集中随机抽取两个样本,其类别不一致的概率,反映了数据集的不确定性。因此,Gini 指数越小,数据集纯度越高,不确定性越低。在每次划分时,选择使得划分后的 Gini 指数最小的特征。
其他决策树生成算法
ID3 算法
ID3 算法使用信息增益作为特征划分的依据,信息增益可以理解为知道某个特征后,获得的信息量大小(或者说信息的不确定性减少的程度)。在计算信息增益之前,我们先介绍熵。
在信息论中,熵表示随机变量或集合的不确定性程度,熵越小,不确定性程度越小,纯度越高。对于集合 \(\mathcal{D}\),其信息熵的计算公式为:
$$H(\mathcal{D})=-\sum_{k=1}^{|\mathcal{D}|}p_{k} \log_{2} p_{k},$$这里,\(p_{k}\) 为第 \(k\) 类样本在 \(\mathcal{D}\) 中所占的比例。当 \(p_{k}=0\) 时,令 \(0 \log 0=0\)。
有了信息熵的概念,我们就可以定义信息增益:
$$\begin{aligned}g(\mathcal{D}, A)&=H(\mathcal{D})- H(\mathcal{D}|A) \\ &=H(\mathcal{D})-\sum_{v=1}^{V}\frac{|\mathcal{D}^{v}|}{|\mathcal{D}|} H(\mathcal{D}^{v}),\end{aligned}$$其中,\(H(\mathcal{D}|A)\) 表示通过特征 \(A\) 划分后各个类别数据集的信息熵之和,\(V\) 是特征 \(A\) 的取值数量。
C4.5 算法
根据信息增益的公式可以看出,信息增益偏好取值数量多的特征,为了解决这个问题,C4.5 算法采用增益率来划分特征:
$$g_{R}(\mathcal{D}, A)=\frac{g(\mathcal{D}, A)}{H_{A}(\mathcal{D})},$$其中,
$$H_{A}(\mathcal{D})=-\sum_{v=1}^{V}\frac{|\mathcal{D}^{v}|}{|\mathcal{D}|} \log_{2} \frac{|\mathcal{D}^{v}|}{|\mathcal{D}|}.$$特征 \(A\) 的取值数量越多,\(H_{A}(\mathcal{D})\) 越大,因此增益率通过除以该值来平衡特征取值数量的影响。
决策树优缺点
优点:
-
解释性强。
-
可以处理离散和连续的特征。
-
对特征的量纲不敏感,不需要标准化数据。
-
在大规模数据集的训练速度也很快。
缺点:
-
决策树在测试集的精度可能不高,因为树的构建采用贪心算法,容易陷入局部最优。此外,过于拟合训练数据,使得树的结构过于复杂,导致过拟合。
-
决策树结果不稳定,对数据非常敏感,这是由它自身的结构导致的,上层结点的错误会不断传导给下层结点。
参考文献
1.Kevin P. Murphy. Probabilistic Machine Learning: An introduction. MIT Press, 2022.
2.李航. 统计学习方法(第 2 版). 北京: 清华大学出版社, 2019.
3.周志华. 机器学习. 北京: 清华大学出版社, 2017.